【論文紹介】Learning Classifiers from Only Positive and Unlabeled Data
はじめに
通常の2値分類問題においては、サンプルxに対してラベルがpositive(y=1)であるかnegative(y=0)であるかが明示的に与えられていることを前提とします。
一方で、現実的な問題設定においてnegativeが明示的に与えられないケースも存在し、そのようなケースに対応しようとするのがpu learningになります。
pu learningの中でも、Learning Classifiers from Only Positive and Unlabeled Data において提案されている方法は実装自体が簡単なのと、以下のようなパッケージが配布されていることもあり使用しやすくなっています。
この記事では、上記論文でどのようなことが行われているのかまとめていきます。
pu learning における問題設定
pu learningにおいては、positiveのみ、かつその一部のみがフィードバックとして明示的に与えられる状況を想定します。
そして、positiveとして明示的にラベルがわかるものをlabeled、明示的なラベルが存在しないものをunlabeledとして扱います。
そのため、inputとなるデータセットのラベルは以下のような構成になります。
- labeled : 潜在的なpositiveのうち観測されたサンプルのみが含まれる
- unlabeled : 潜在的なpositiveなサンプルのうち観測されなかったサンプル、潜在的にnagativeな全てのサンプルが含まれる
このようなデータセットにおいて、labeledをpositive、unlabeledをnegativeとして扱って学習してしまうと、本来の確率分布とは異なる予測値になってしまうことが想定されます。具体的には、本来の分布よりも全体的に低い確率での予測値が得られることになります。
このようなケースにおいて、本来の確率分布をできるだけ再現することが pu learning における問題設定になります。
また、labeledはpositiveの全てが含まれる訳ではないですが、labeledであればpositiveなので、positive vs unlabeledでの2値分類問題として、pu(positive unlabeled) learning, pu classification という呼び方が定着しているように思います。そのため、この記事ではこちらの呼び方を使用します。
Learning Classifiers from Only Positive and Unlabeled Data
こちらの論文では、
- 2値分類モデルの出力値をpu分類の出力値としてcalibrationする方法
- puデータセットを元に重み付き分類問題へ落とし込む方法
の2つの方法が提案されています。
論文内で明確に手法名が定義されている訳ではないのですが、上記パッケージにおいて著者名を使用し前者はElkanoto、後者はWeighted Elkanotoと呼ばれているので、こちらでもその呼び方を使用します。
全てのpositiveのうち、labeledとして観測されるpositiveはxの値に関わらず発生するという仮定(Selected Completely At Random assumption)をおくことが特徴となっています。
Selected Completely At Random assumption
こちらの論文においては、全てのpositiveのうち、labeledとして観測されるpositiveはxの値に関わらず発生するという仮定
つまり、
- positive: y=1, negative: y=0
- labeled: s=1, unlabeled: s=0
と表記したとき、以下が成り立つという仮定を、Selected Completely At Random assumption(SCAR仮定)と呼びます。

提案手法1: Elkanoto
2値分類モデルの出力値をpu分類の出力値としてcalibrationする方法です。
定期化
上記SCAR仮定より、labeled=positiveである確率p(s=1|x)は

となるので、
- 通常のpositiveとnegativeに対する予測値 p(y=1|x) を出力する関数: f(x)
- labeledとunlabeledから学習した p(s=1|x) を出力する関数: g(x)
とおいたときに、f(x) は g(x) / p(s=1|y=1) により求めることができます。
また、ここでlabeledは全てpositiveである、つまり

となります。
ここから、validation setにおけるlabeledのみを含むデータセットをPとおいた時、

より、p(s=1|y=1) の値はvalidation setにおけるlabeledサンプルに対する g(x) の出力の平均値として推定可能です。
つまり、labeledとunlabeledから学習した関数 g(x) の出力を、validation setにおけるlabeledサンプルに対する g(x) の出力の平均値で割ったものが、positiveとnegativeの2値分類としての出力となります。 決定境界をnegativeに向けてずらすイメージですね。
手順
具体的な手順としては、以下になります。
- puデータセットから通常の分類モデルを学習
- validation setのpositiveに対する分類モデルの予測値を平均し、p(s=1|y=1)を求める
分類モデルの予測値 / p(s=1|y=1)がcalibrationされた予測値となる
提案手法2: Weighted Elkanoto
puデータセットを元に重み付き分類問題へ落とし込む方法です。
上記SCAR仮定より、

であることがわかるので、ある関数 h(x) の期待値 E[h(x)] は以下のように変換できます。

このことから、unlabeledなサンプルは
p(y=1|x, s=0)の重みを持つpositiveサンプル1 - p(y=1|x, s=0)の重みを持つnegativeサンプル
で構成されると見なすことができます。
本論文ではこれを利用して、unlabeledデータセットを複製し、片方にp(y=1|x, s=0)の重みを、もう片方に1 - p(y=1|x, s=0)の重みを持たせることで、重み付き学習として扱うことを提案しています。
検証
DeepFMを使用して、手法1として紹介したElkanotoの検証を行いたいと思います。
実装
以下が実装になります。
検証方法などに関しては、上記パッケージにおける検証を参考にしています。
データセット
MovieLens 100K Datasetを使用します。
positiveとnegativeの問題設定とするため、ratingが4以上のものをpostive、3以下のものをnegativeとして使用します。
検証方法
positiveのうち、一定割合がunlabeledである。つまりpositiveとして観測できなかったというケースを考えます。
具体的には、
の二つを用意し、両者共にtrain(validation) setのみに対して、positiveのうち一定割合をランダムでunlabeledに変換します。
これらデータセットで学習したモデルを使用することで、通常のpositive negativeで学習したDeepFMとElkanoto間で、unlabeledが占める割合ごとの精度差を比較します。
評価指標としては、論文でも使用されているf1 score(threshold=0.5)を使用します。
検証結果
下図のように、positiveのうち観測できなかった割合、つまりunlabeledな割合が増えるほど、通常のDeepFMではf1-scoreが大きく下がるのに対して、Elkanotoで補正した場合はあまり下がらないという結果が得られました。

最後に
この論文ですが後続の研究では、全てのpositiveサンプルに対して p(s=1|y=1) が一つしか存在しないという点で非現実的であると書かれています。
また、Elkanotoにおいて、validation set内のpositiveの平均で割ってしまうと補正後の予測値が1を越えることがあるので、何かしら補正する必要があるのかもしれません
追記
こちらの後続の論文に関して、以下でそれぞれまとめています。
参考文献
LightFMで前処理・学習から予測・評価・潜在表現の取得までやってみる

概要
こちらのLightFMを実際にMovieLensのデータを使って一通り動かしてみます。 github.com
元になっている論文はこちらです。 arxiv.org
細かい論文の内容に関しては以下の記事でまとめています。 nnkkmto.hatenablog.com
また、動かすことが目的であるため精度に関してはこの記事では考えません。
論文概要
user, itemの潜在表現をuser, itemそれぞれのメタデータの潜在表現のsumとして表現することで、
- user, itemのメタデータに関してもMatrix Factorizationのように類似度を元にした潜在表現の学習を行う
- Matrix Factorizationにおけるcold-start問題に対処する
というものがLightFMで、user×itemのinteractionのみを考慮するという点においては、全特徴量間のinteractionを考慮するFactorization Machinesの特殊系というかLightになったバージョンと言えます。
流れ
以下のような流れで使い方をみていきます。
- lightfm.data.Datasetを用いた前処理
- 学習
- 潜在表現の取得
- 既存ユーザーに対する予測
- 新規ユーザーに対するfeatureを用いた予測
- lightfm.evaluationを用いた評価(recall@4)
使用するデータセット
MovieLens 100K Dataset | GroupLens からratingが4以上のinteractionのみを抜き出し、整形した以下のようなテーブルを使用します。

使用したスクリプト
今回使ったスクリプトは以下レポジトリに格納しています。 github.com
lightfm.data.Datasetを用いた前処理
LightFMの学習時の入力値としては、
- interaction matrix: shape=(n_users, n_items)
- user feature matrix: shape=(n_users, n_user_features)
- item feature matrix: shape=(n_items, n_item_features)
があります。interaction matrixが教師ラベルとなるuser×itemのinteractionを含む行列です。
user, item feature matrixは各user, itemに結びつくfeatureをあらわす行列で、user, item embeddingはこれらfeatureのembeddingのsumで表現されます。
ここで、user, item feature matrixは任意で、両方とも入力しない場合はMatrix Factorizationになります。
これらLightFMへの入力の構築をencoding含めてやってくれるのがlightfm.data.Dataset になります。
概要
また、lightfm.data.Datasetにおける手順としては、
- user_id, item_idを含む各種特徴量における値のユニーク値を元にencoder生成(fitメソッド)
- 各種データセットのビルド(build_*メソッド)
という流れになります。
まず、存在する特徴量をuser_id, item_id含めてencoderに登録し、build_*メソッドにより入力をone-hot encodingすることによりmatrixにするという形になっています。
また、lightfm.data.Datasetへの入力形式に関して、
こちらのissueにある通り、build_*メソッドにおいては特徴量の重みを指定しない場合は以下のような入力形式になります。
interactions = [
("user_A", "item_X", 0),
("user_A", "item_Y", 5),
("user_A", "item_Z", 1),
("user_B", "item_X", 1),
("user_C", "item_Y", 5),
]
users_features = (
["user_A", ["user_feat1", "user_feat2"]],
["user_B", ["user_feat3", "user_feat4", "user_feat2"]],
["user_C", ["user_feat1", "user_feat4"]],
)
items_features = (
["item_X", ["item_feat1"]],
["item_Y", ["item_feat2", "item_feat3", "item_feat4"]],
["item_Z", ["item_feat1", "item_feat3", "item_feat4"]]
)
特徴量の重みを指定する場合は、こちらのissueにある通り、
users_features = (
["user_A", {"user_feat1": 1, "user_feat2": 3}],
["user_B", {"user_feat3": , "user_feat4": 1, "user_feat2": 2}],
["user_C", {"user_feat1": 0.5, "user_feat4": 1}],
)
のように、feature名のlistになっているところをfeature名: weight のdictとして渡すことで指定可能です。
ここで、interactionsは0 or 1つまりimplicit feedbackの問題設定である場合はratingが省略可能です。
また、特徴量間で同じ値を使用している際は、prefixとして特徴量名をfeatureの値に付与しておくなどして値の重複を防いだ方が良いように思います。
dataframeからの変換
こちらのデータセットから、以下のようにDatasetの入力形式へ変換します。
# prefixの付与 df["age"] = "age-" + df["age"].astype(str) df["gender"] = "gender-" + df["gender"].astype(str) df["occupation"] = "occupation-" + df["occupation"].astype(str) df["release_date"] = "release_date-" + df["release_date"].astype(str) df["genre"] = [["genre-" + value for value in i] for i in df["genre"].values.tolist()] # user, item 特徴量の結合 df["user_features"] = df[["age", "gender", "occupation"]].values.tolist() df["item_features"] = df[["release_date", "genre"]].values.tolist() # list of listになっているレコードをflatten def flatten_sequences(sequences): sequences = [i if type(i) == list else [i] for i in sequences] flattened = list(itertools.chain.from_iterable(sequences)) return flattened df["item_features"] = df["item_features"].apply(flatten_sequences) df = df[["user_id", "movie_title", "user_features", "item_features", "timestamp"]] df

また、評価時に使いたいので、全体のデータセットから各ユーザーに対してtimestampが最大、つまり最新のinteractionを抽出したものをtest setとして用意します。
df_test_indices = df.groupby("user_id") df_test = df.loc[df_test_indices['timestamp'].idxmax(),:] df_test

train setとしてはそれ以外のinteractionを使用します。
df_test["test_flag"] = 1 df_train = pd.merge(df, df_test[["test_flag"]], how="left", left_index=True, right_index=True) df_train = df_train[df_train["test_flag"].isnull()].drop(columns=["test_flag"]) df_train

encoderの生成
上記datasetからencoderを作成します。
user_id, item_id, user_feature, item_featureそれぞれの値をユニークで取得し、それを入力としてencoderを生成します。
# user, item featureは全て既知として、既存のレコード全てからマスタを作成 uq_users = np.unique(df.user_id.values) uq_items = np.unique(df.movie_title.values) uq_user_features = np.unique(np.array(flatten_sequences(list(df.user_features.values)))) uq_item_features = np.unique(np.array(flatten_sequences(list(df.item_features.values)))) dataset = Dataset() dataset.fit(uq_users, uq_items, item_features=uq_item_features, user_features=uq_user_features)
datasetのビルド
以下のように、datasetへの入力形式に変換します。
# train interaction matrix df_train_interactions = df_train[["user_id", "movie_title"]].drop_duplicates() train_interactions = list(df_train_interactions.itertuples(index=False, name=None)) # [(user_id, item_id), ...] # test interaction matrix df_test_interactions = df_test[["user_id", "movie_title"]].drop_duplicates() test_interactions = list(df_test_interactions.itertuples(index=False, name=None)) # [(user_id, item_id), ...] # user feature matrix df_user_features = df[["user_id","user_features"]].drop_duplicates(subset='user_id').set_index('user_id') user_features = list(df_user_features.itertuples(index=True, name=None)) # (user_id, [feature1, feature2, ...]) # item feature matrix df_item_features = df[["movie_title","item_features"]].drop_duplicates(subset='movie_title').set_index('movie_title') item_features = list(df_item_features.itertuples(index=True, name=None)) # (item_id, [feature1, feature2, ...])
そして、それを各build_*メソッドへ渡すことで、LightFMへの入力を得ることができます
# implicit feedbackのため、weightつきのinteractionは使用しない
train_interactions, _ = dataset.build_interactions(train_interactions)
test_interactions, _ = dataset.build_interactions(test_interactions)
user_features = dataset.build_user_features(user_features)
item_features = dataset.build_item_features(item_features)
ここで、build_interactionsからは0 or 1つまりimplicitなinteractionと重み付きのinteractionの二つが返ってきますが、今回はimplicit feedbackを扱うため後者は使用しません。
また、LightFMにおいてはuser, itemのidもfeatureの一つとして扱うため、build_user_features build_item_features の返してくるmatrixの列にはidも含まれます。
そのため、例えばuser_featuresのshapeは正確には(n_users, n_users+n_user_features)となります。
mappingの取得
以下のように、featureとidとmatrixにおけるindexのmappingは以下のようにして取得可能です。
これを使用して、予測結果のmatrixを簡単にid名やfeature名で確認できたりするようになっています。
user_id_map, user_feature_map, item_id_map, item_feature_map = dataset.mapping() print(f"index of user_feature age-48: {user_feature_map['age-48']}") print(f"index of item_feature Full Monty, The (1997): {item_feature_map['Full Monty, The (1997)']}")
index of user_feature age-48: 979 index of item_feature Full Monty, The (1997): 498
また、前述のuser, item_featuresと同じく、user, item_feature_mapにはuser, item_idのmappingも含まれます。
そのため、例えばlen(user_id_map) == n_user len(user_feature_map) == n_users+n_user_features となります。
連続値を入力とする場合
ここでは扱いませんが、連続値を入力する場合は前掲のissueにあるように、特徴量の重みを指定することで変換してくれます。 ここで、連続値に対してはカテゴリー値とは違い、値ではなく特徴量名をfitに渡すことになります。
例えば、ageを連続値として渡す場合は以下のようになります。
dataset = Dataset()
dataset.fit([1, 2], uq_items, user_features=["age"])
# 見やすいようにnormalizeしないようにする
user_features = dataset.build_user_features([[1, {"age": 20}], [2, {"age": 10}]], normalize=False) # [[user_id, {feature1: weight, ...}, ...], ...])
print(user_features.toarray())
# 1, 2列目がuser_id、3列目が連続値として渡したage
array([[ 1., 0., 20.],
[ 0., 1., 10.]], dtype=float32)
学習
学習時は、生成済みの入力を渡して完了です。 no_componentsがembeddingの次元です。
model = LightFM(no_components=10, loss='warp') model.fit(train_interactions, item_features=item_features, user_features=user_features, epochs=100)
また、epochsは100で設定していますが、デフォルトだと
- epochs: 1
- user_alpha , item_alpha(user, item embeddingに対するL2正則化): 0.0
という設定になっていて、データセットによるとは思いますがデフォルトの設定そのままだとうまく学習できないような気がします。
潜在表現の取得
学習済みのモデルから
- 各種featureの潜在表現
- user, itemの潜在表現
を取得することができます。
各種featureの潜在表現
学習済みのモデルには user_embeddings item_embeddings として、各種featureのembeddingが格納されており、(n_users, 指定したembeddingの次元), (n_items, 指定したembeddingの次元) の行列が取得できます。
そのため、datasetで作成されたmappingを使用すれば、以下のように簡単に各値のembeddingを取得することができます。
user_id_map, user_feature_map, item_id_map, item_feature_map = dataset.mapping() # user embeddingの取得 user_embeddings = model.user_embeddings mapped_user_embeddings = {name: user_embeddings[index] for name, index in user_feature_map.items()} print("Embedding: gender-F") print(mapped_user_embeddings["gender-F"]) # item embeddingの取得 item_embeddings = model.item_embeddings mapped_item_embeddings = {name: item_embeddings[index] for name, index in item_feature_map.items()} print("Embedding: MatchMaker, The (1997)") print(mapped_item_embeddings["MatchMaker, The (1997)"])
Embedding: gender-F [-2.3874125 0.9395195 -2.2523065 -6.961481 -0.7835085 4.270282 -0.47744742 0.6703578 6.288997 5.106352 ] Embedding: MatchMaker, The (1997) [ 0.48336646 0.1213533 0.6352143 0.08677411 0.5721241 -0.5955509 0.6072041 -0.3372576 -0.7195242 -0.93152696]
user, itemの潜在表現
前述の通りLightFMでは、user, itemのembeddingはuser feature, item featureのembeddingを足し合わせたものとして表現されます。
そのため、featureを元にそのuserやitemのembeddingを取得するメソッドもget_user_representations get_item_representations として用意されています。
以下のように、各featureの値を学習に使用したdatasetのmappingを用いて、LightFMの入力であるuser_featuresとしてcsr_matrixに変換します。
それを渡すことで、get_user_representations ならそのfeatureを持つuserのembeddingとそのbiasを返してくれます。get_item_representations に関しても同様の手順となります。
user_id_map, user_feature_map, item_id_map, item_feature_map = dataset.mapping() def create_matrix_with_user_features(user_features): # csr_matrixに変換 col = np.array([user_feature_map[key] for key in user_features]) row = np.repeat(0, len(user_features)) data = np.repeat(1, len(user_features)) user_matrix = csr_matrix((data, (row, col)), shape=(1, len(user_feature_map))) return user_matrix user_features = ["age-33", "gender-F", "occupation-administrator"] user_matrix = create_matrix_with_user_features(user_features) bias, embeddings = model.get_user_representations(features=user_matrix) print(f"bias: {bias}") print(f"embedding: {embeddings[0]}")
bias: [-195.15112] embedding: [-4.9082627 -1.2549659 -4.376274 -8.901307 -2.6249416 4.056341 -1.5262341 2.209255 7.078497 6.1518583]
予測
既存user, itemに対する予測
学習時に存在していたユーザーに対しては、user_ids, item_idsに学習で渡したinteractionにおけるindexを渡せば対象のユーザーの対象のアイテムに対する予測を返してくれます。
# 学習時のinteraction matrixにおける、0行目のuserの[0,1,2]列目のitemに対するscore predictions = model.predict(user_ids=0, item_ids=[0,1,2]) print(predictions)
array([-15.714636 , -11.901891 , -13.5374365], dtype=float32)
また、datasetのmappingを使用することで、indexではなく本来のuser_idに対して本来のitem_idへの予測結果の確認を行うことが簡単にできます
ここでは、以下のuser_id=873のユーザーに対する全アイテムの予測結果をdataframeに格納して表示してみます。
df_train[df_train["user_id"] == 873]

user_id_map, user_feature_map, item_id_map, item_feature_map = dataset.mapping() # user_idに対して、全アイテムへの予測値を格納したdfを返す def predict_all_items_by_user_id(user_id): user_index = user_id_map[user_id] predicted = model.predict(user_ids=user_index, item_ids=np.array(range(0,len(item_id_map)))) return make_predict_df(predicted) def make_predict_df(predicted): df_predicted = pd.DataFrame.from_dict(item_id_map, orient='index').rename(columns={0: "item_index"}).sort_values(by="item_index") df_predicted["score"] = predicted df_predicted = df_predicted.sort_values(by="score", ascending=False) return df_predicted[["score"]] predict_all_items_by_user_id(873)

新規user, itemに対する予測
こちらのissueにあるように、predict において、上記のようにuser_ids item_ids のみを渡した場合は、それらは学習時のinteractionにおけるindexを意味するんですが、user_features item_features を一緒に渡した場合はそれらfeaturesのmatrixにおけるindexを意味するようになります。
そのため、新規user, itemに対してはuser_id, item_idが全て0であるuser_features, item_featuresを渡し、そのfeaturesにおけるindexをidsとして指定することで予測結果を得ることができます。
以下では user_features = ["age-48", "gender-F", "occupation-administrator"] である新規userに対する全アイテムの予測結果を表示しています。
def predict_all_items_by_user_features(user_features): # user_featuresをmatrixに変換 col = np.array([user_feature_map[key] for key in unknown_user_features]) row = np.repeat(0, len(unknown_user_features)) data = np.repeat(1, len(unknown_user_features)) user_features = csr_matrix((data, (row, col)), shape=(1, len(user_feature_map))) # predict predicted = model.predict(user_ids=0, item_ids=np.array(range(0,len(item_id_map))), user_features=user_features) return make_predict_df(predicted) unknown_user_features = ["age-48", "gender-F", "occupation-administrator"] predict_all_items_by_user_features(unknown_user_features)

predict_rank
その他の予測用のメソッドとしてpredict_rankが用意されています。
こちらのissueにあるように、test_interactionsとして渡した行列においてnon-zeroになっているuser×itemが、そのuserの全itemに対するスコアの中で上位何位になっているかを含む行列を返してくれるメソッドになっています。 そのため、test_interactionsとしてはランクを知りたいuser×itemのindexがnon-zeroになっている(n_users, n_items)の行列を用意します。
ここでは、上記で用意したtest setをinteractionに変換したものを渡します。 また、item_featuresとuser_featuresは
model.predict_rank(
test_interactions=test_interactions, user_features=user_features,
item_features=item_features)
predict_rankにおける注意点
Performs best when only a handful of interactions need to be evaluated per user. If you need to compute predictions for many items for every user, use the predict method instead.
predict_rankのドキュメントに上記の記載があるように、predict_rankはuserに対するitemのinteractionが多くなるとパフォーマンスが落ちるようです。
そのため、こちらのissueにある通り、あるuserに対して全itemのランクが知りたいという場合においてはpredictメソッドを使用した方が良いです。
評価
ここでは、train setに存在する全userに対して4件のitemを予測した際に、その中にuserが次にratingをつけるitemが含まれるかを問題設定とします。*1
方法としては、userの最新のinteractionを抽出したものをtest set、それ以外をtrain setとしてrecall@4での評価を行います。
また、全てのuser, itemが学習時に既知であると仮定します。
前述の前処理で用意したdatasetを元に同じようにLightFMへの入力形式に変換します。
df_test_interactions = df_test[["user_id", "movie_title"]].drop_duplicates() test_interactions = list(df_test_interactions.itertuples(index=False, name=None)) # [(user_id, item_id), ...] test_interactions, _ = dataset.build_interactions(test_interactions) # shape=(n_users, n_items)のcsr_matrix
そして以下で各userに対するrecall@4が返ってきます
# 全てのuser, itemが既知であるとするため、学習時に生成したuser_featuresとitem_featuresを使用する recalls = evaluation.recall_at_k(model, k=4, test_interactions=test_interactions, user_features=user_features, item_features=item_features) print(recalls.mean())
結果は0.0031847133757961785でした。今回の問題設定だと942人のuserのうち3人にのみ正解したという結果になっています。
また、その他の評価指標に関しても同じインターフェースで使用できます。
# recall_at_kと同じくuserごとの結果が格納された配列が返ってくる precisions = evaluation.precision_at_k(model, k=4, test_interactions=test_interactions, user_features=user_features, item_features=item_features) aucs = evaluation.auc_score(model, test_interactions=test_interactions, user_features=user_features, item_features=item_features)
評価時の注意点
上記のどのメソッドもpredict_rankを内部で使用しているため、同じくuserに対するitemのinteractionが多くなるような問題設定で評価を行う場合は、predictメソッドを使用し他のパッケージもしくは自作の評価関数で評価する形が良いように思われます。*2
最後に
書いたようにいくつか注意点やわかりづらい仕様があり困りましたが、手軽にFactorization Machines系モデルを使えるという点ではかなりLightFMいい感じです。
【論文紹介】LightFM: Metadata Embeddings for User and Item Cold-start Recommendations
はじめに
以下でLightFMとしてパッケージも配布されている Metadata Embeddings for User and Item Cold-start Recommendations を読んでいきます
このパッケージ、lossや前処理などメソッドがかなり充実していて使いやすく、またLightFM自体も予測精度いいのでおすすめです。explicit feedbackを扱えないというところのみ注意が必要です。
追記:LightFMの使用方法に関して以下記事にまとめました
概要
- FMのspecial caseとして捉えられる
- 全てのfeature間のinteractionを考慮するFactorization Machinesとは異なり、userとitem間のinteractionのみを考慮する
- user, itemに紐付く特徴量のembeddingのsumをとったものをuser, itemのembeddingとしてmatrix factorizationをするため、user, item両方のcold-start問題に強い
モチベーション
- userとitemのinteractionを元に類似するかどうかを学習すること
- user, item両方のcold-start問題を解決すること
従来手法において、前者はMatrix Factorizationで実現できる一方で、後者はできません。また、contents-basedなcollaborative filteringでは後者をある程度緩和できますが、user, itemの各種特徴量同士の類似は考慮されません。
また、こちらLystというファッションECのサイトからの論文なんですが、
- 年ごと、季節ごとに商品が変わるため、新商品が多い
- 1回切りの購買をするユーザーが多い
- 商品自体が非常に多い
という課題があったことが、後者の背景にあるようです。
モデル
入力
ユーザーにひもづく特徴量とアイテムにひもづく特徴量を入力とします。
例えば、アイテムが映画だとすれば、「タイトル」「主演」「ジャンル」、ユーザーに対しては「ユーザーID」「性別」「年代」といった情報がそれぞれ入力となります
モデル概要
簡単には、以下のようなモデルになっています
- 入力となる特徴量から次元dのembeddingをそれぞれ取得
- ユーザーにひもづく特徴量のembeddingからsumをとったものをユーザーのembeddingとする
- アイテムにひもづく特徴量のembeddingからsumをとったものをアイテムのembeddingとする
- 作成したユーザーのembeddingとアイテムのembeddingからinteractionを学習する
定式化
各種特徴量のembedding(d次元)をeとおいたときに、ユーザーembeddingは、ユーザーにひもづく特徴量のembeddingの総和であるd次元のベクトルとなります。

同じく、アイテムembeddingは、ユーザーにひもづく特徴量のembeddingの総和であるd次元のベクトルとなります。

また、ユーザー・アイテム特徴量それぞれに対してscalar値のbiasを持つようにし、それぞれの総和がユーザー・アイテムのバイアス(bu, bi)となります。


そして、ユーザーembeddingとアイテムembeddingのdot積をとったものに、ユーザー・アイテムバイアスを足し合わせたものに対して、関数fを適用したものがモデルの出力になります。

論文では、関数fとしてsigmoid関数を使用しています。
ここから、lossは以下のようになります

MF・FMとの違い
ユーザー・アイテムembeddingを、ユーザー・アイテム特徴量から作成しない場合、つまりそれぞれにembeddingを用意してinteractionをとった場合、Matrix Factorizationになります。
また、Factorization Machinesは、全ての特徴量間のinteractionを考慮しますが、LightFMが考慮するのはuser, item間のinteractionのみです。
また、Factorization Machinesとは違い、ユーザー・アイテム特徴量からユーザー・アイテムembeddingを作成するという処理が行われています。
最後に
- FMに関しても同じだが、embeddingの作成方法に関しても工夫が効く
- sequencialな特徴量をpoolingして使うだったり転移学習したりできる
参考文献
【論文紹介】Factorization Machines
Factorization Machinesを読んで実装してみました
論文内容
課題
既存手法として、SVMやMatrixFactorizationが存在するが、
- レコメンドでよくある問題設定、つまりカテゴリー値が多い(=sparseである)入力において、SVMだと非線形なカーネル空間となるため安定してパラメータを学習できない
- matrix factorizationはsparseな入力をうまく学習できるが、2種類の特徴量間の交互作用のみしか考慮できない
そのため、sparseな入力に対してもmatrix factorizationのようにうまく学習ができて、一方でSVMのように様々な特徴量を入力できるモデルとして、Factorization Machinesを提案
想定する入力
下記のように、UserのItemに対する評価をターゲットラベルとして、User*Itemの値でユニークとなる
- one-hot(User, Movie, Last Movie Rated)
- multi-hot(Other Movie Rated)
- 連続値(Time)
で構成された入力を考えます。

Factorization Machines

equationはこちらになります。 ここで、nがfeature数、iが何次元目のfeatureかを示します。
そして、左項がlinear regressionで、各featureに対して単純に重みを掛け合わせて足し合わせたもの。 右項がfeature同士の交互作用を考慮するもの(feature intaractions)になっています。
ここで、kをハイパーパラメータである潜在ベクトルの次元として、

であり、対象となる2種類のfeatureの潜在ベクトル間の交互作用を考慮するものになっています。
xixjは両方のfeatureにおいて値が存在するか(=0でない)を表すシグナルとなっています。
このことから、例えば、上記入力の7行目のレコードを考えると、

右項は、
<UserC, vMovieSW> + <UserC, vOtherMoviesTI> + <UserC, OtherMoviesSW> + ... + <OtherMoviesSW, Time> + <Time, LastMovieTI>
といった組み合わせでそれぞれ潜在ベクトルのdot積が計算されていくというのが、右項のやっていることになります。 またここで、各featureの潜在ベクトルは同じ一つの潜在空間に属します。
なぜsparsityに強いのか
課題として、汎用的な入力を受け付けることとsparsityに強いことが挙げられていましたが、前者に関しては既に明確ですが、後者に関しては、存在しないfeature間の組み合わせに対しても、類似する組み合わせを元に推定できるからというのが理由になります。
feature間の組み合わせ間でそのラベルの値が類似する場合に、その交互作用同士は類似すると考えられるため、類似する組み合わせに含まれるfeatureも、潜在空間において近い位置にあると考えられるためです。
multi-way Factorization Machines
上記Factorization Machinesでは一つの組み合わせに対して2種類のfeature間の交互作用のみを考慮しましたが、それ以上の種類を考慮することが下式のように可能です。
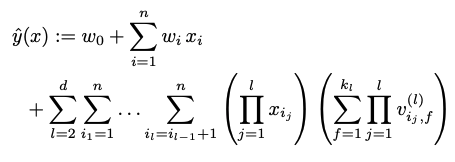
例えば3-way、つまり3種類のfeature間の交互作用を考慮する場合は、上記の例だと以下のような組み合わせになります。
<UserC, vMovieSW, vOtherMoviesTI> + <UserC, vOtherMoviesTI, OtherMoviesSW> + ... + <OtherMoviesSW, Time, LastMovieTI>
ただ、こちらは計算コスト的に厳しそうです。
実用時の注意点
計算コストの削減
上記Factorization Machinesにおけるequationだと、全てのfeature間の組み合わせを計算する必要があるため、計算コストはfeature数nに対して2乗分増えていきます。 その代替案として、右項を以下のように変形することで、feature数に対して線形に増加するように計算コストを下げることができます。

モデルを実装する際は右項をこちらに置き換えてやる必要があります。
潜在ベクトルの次元kの設定
理論上は、kの値が充分以上大きければ、どんな交互作用でも表現可能となります。 ただ、データセットの中に全通りの組み合わせが存在することは稀であるため、通常はそれ以下の値で設定するのが良いとのことです。
また、汎化性能を上げる、つまりモデルの表現力を抑制するためにkの値を小さくすることも考えられます。
実装
モデルの実装は以下になります。
- Embedding Layerを動的に作成したかったため、initでfeatureの情報を渡している
- Embedding Layerでsequencialな特徴量を扱えるようにしている
ため、Embedding Layerのみ少し複雑になっています。
from collections import OrderedDict import tensorflow as tf class EmbeddingLayer(tf.keras.layers.Layer): def __init__(self, features_info, emb_dim, name_prefix=''): """ sequence対応のembedding layer """ super(EmbeddingLayer, self).__init__() self.features_info = features_info self.feature_to_embedding_layer = OrderedDict() for feature in features_info: initializer = tf.keras.initializers.RandomNormal(stddev=0.01, seed=None) if feature['is_sequence']: # sequenceのembedding self.feature_to_embedding_layer[feature['name']] = tf.keras.layers.Embedding( feature['dim'], emb_dim, mask_zero=True, name=f"embedding_{name_prefix}{feature['name']}", embeddings_initializer=initializer) else: self.feature_to_embedding_layer[feature['name']] = tf.keras.layers.Embedding( feature['dim'], emb_dim, name=f"embedding_{name_prefix}{feature['name']}", embeddings_initializer=initializer) def concatenate_embeddings(self, embeddings, name_prefix=''): if len(embeddings) >= 2: embeddings = tf.keras.layers.Concatenate(axis=1, name=name_prefix+'embeddings_concat')(embeddings) else: embeddings = embeddings[0] return embeddings def call(self, inputs): embeddings = [] for feature_input, feature in zip(inputs, self.features_info): # embeddingの作成 embedding = self.feature_to_embedding_layer[feature['name']](feature_input) if feature['is_sequence']: # sequenceの場合はaverage pooling embedding = tf.math.reduce_mean(embedding, axis=1, keepdims=True) embeddings.append(embedding) # concatenate embeddings = self.concatenate_embeddings(embeddings) return embeddings class FactorizeLayer(tf.keras.layers.Layer): def __init__(self, features_info, latent_dim=5): super(FactorizeLayer, self).__init__() self.embedding = EmbeddingLayer(features_info, latent_dim, 'factorize_') def call(self, inputs): # factorization embeddings = self.embedding(inputs) # 元論文のlemma 3.1 summed_square = tf.square(tf.reduce_sum(embeddings, axis=1)) squared_sum = tf.reduce_sum(tf.square(embeddings), axis=1) output = tf.subtract(summed_square, squared_sum) output = tf.multiply(0.5, tf.reduce_sum(output, axis=1, keepdims=True)) return output
最後に
- 存在しない組み合わせに対しての推定が可能
- interaction以外の特徴量も入力可能(性別とか)
という2点から、User*Itemのレコメンドを考えたときに、コールドスタートに非常に強いモデルであるように思いました。
【論文紹介】LightGBM: A Highly Efficient Gradient Boosting Decision Tree
ちゃんと論文読んでなかったので、、、
課題
GBDTにおいて、最も計算コストのかかるのが決定木の学習、その中でも分岐の決定。
従来のGBDTにおいては、全てのあり得る分岐点を考慮するため、全てのレコードを元に学習を行うため、以下の二つが増えるごとに、計算コストも上がる。
- レコード数
- 特徴量数
モデルで扱うレコード数と特徴量数を共に減らせれば、計算効率がよくなって、データ数多くてもfeature数多くてもGBDTが実用的な学習速度で使用できるようになるっていう内容
提案手法概要
Gradient-based One-Side Sampling (GOSS)
- レコード数を減らすアルゴリズム
- lossの減少への貢献が大きいレコードと、小さいレコードという二つの集合に分けて、小さいレコードに対してランダムサンプリングすることでレコード数を減らす
- 単純にレコード数減らすと分布が変わってしまうので、それを考慮している
Exclusive Feature Bundling (EFB)
- 特徴量数を減らすアルゴリズム
- 同じレコードにおいて同時にnon zeroにならない(もしくはなるが許容量である)特徴量をカテゴリー値に変換し、さらに一つの特徴量としてまとめることで減らす
※ 同じレコードにおいて同時にnon zeroにならない特徴量=one-hotだったり許容量であるという意味だとbag of wordsなど
GBDTにおけるsplitアルゴリズム
分岐点を探索するアルゴリズムは2種類
pre-sorted
- 特徴量の値をソートして、全ての分岐点を探索する
- 最適な分岐点が見つかるが、効率が悪い
histogram-based
- 値をbinで区切り、そのヒストグラムを使用する
- 効率が良い
論文における問題意識
ここで、より効率が良い、つまり実用的であるhistogram-basedを使用したいが、pre-sortedはsparseな特徴量において本来無視すべき0の値を無視できる一方、histogram-basedだとそれができない。0を0という値として扱ってしまうため、sparseな特徴量に対して学習効率が悪くなってしまう。
そのため、histogram-basedでsparseな特徴量における0を無視できるようにする必要がある。
※ XGBoostではpre-sorted, histogram-based共にサポートしている
提案手法詳細
各提案手法の詳細
Gradient-based One-Side Sampling (GOSS)
概要
- lossの減少への貢献が大きいレコードと、小さいレコードという二つの集合に分けて、小さいレコードに対してランダムサンプリングすることでレコード数を減らす
- 単純にレコード数減らすと分布が変わってしまうので、それを考慮している
手順

- レコードを勾配の絶対値で降順に並び替える
- 上位a件を部分集合Aとして取得
- 残りの(1-a)件からb件を部分集合Bとしてランダムサンプリング
- AとBの和集合を元に以下の式でIGの推定値を計算(Bのレコードに対しては定数(1-a)/bで重みづけされている)

※ 本来のIG

Exclusive Feature Bundling (EFB)
概要
同じレコード内で同時にnon zeroとならない特徴量(one-hotなど)同士を、一つの特徴量(bundle)としてまとめることで、特徴量数を減らす。 その際に、基本的には削減前と全く同じfeature histogramとなるようにする。つまり、元の特徴量を100%保持する。
以下の二つの手順で構成される
- マージする特徴量の組み合わせ探索
- マージの実行
重複の許容量
nonzeroの値が重複することはあるが、基本的にほとんど重複しない特徴量同士(bag of wordsなど)もまとめたい そのため、conflict(=重複度合い)の許容量を決めて、最適な特徴量同士でまとめるようにする
- γ=許容できるmaxのconflict rate
- (1-γ)nがconflictのないレコード数の最小値となる
マージする特徴量の組み合わせ探索
- グラフを用いた方法
- 用いない方法
の二つがある。後者は前者が計算コスト的にきつい時のための代替案
手順(グラフを用いた方法)

※ K=γn(conflict rate*レコード数)
- 各特徴量をノード、conflictの度合いを重みつきエッジとしたグラフを構築
- 重複度合いの大きさの総和で降順にソート
- 大きいものから、γを元に既存のbundleに入れるか、新しいbundleを作成して入れるかを決定する
手順(グラフを用いない方法)
上記手順だと、feature多すぎると計算コスト高くなるので、featureが数百万ある場合はこちらの方法を使う
- non zeroの値が多い=conflictしやすいとみなせるため、上記1.2.においてグラフを作成せず、特徴量ごとのnon zeroの値の総和でソートする。
- 3.は共通(と書いてあるがconflict countどう求めるかは不明)
特徴量のマージ

histogram-basedアルゴリズムにおいて、binの作成時に、bundle内のfeatureのvalue同士が被らないようにoffsetを追加することによりマージする
例えば、
- [0, 10)の値をとるfeatureA
- [0, 20)の値をとるfeatureB
の二つで構成されるbundleの場合、Bにoffset=10を追加し、Bを[10, 30)に変換する。
それにより、[0, 30)の値をとる一つのfeatureとして使用可能になる
まとめ
- one-hotやbag of wordsみたいなスパースな特徴量を、カテゴリー値に変換することでdenseにする
- その上で、重複がない(もしくは許容できる)特徴量同士をマージする
この二つの処理を通して、特徴量を削減している。
思ったこと
学習時における計算効率を上げるために本来必要なかった処理を挟むという内容で推論速度への改善はないので、学習速度上がる代わりに追加した処理分推論速度は遅くなるのではないかと思った
一方で、EFBがあるからこそカテゴリー値やnull値をそのまま入力として許容してくれるというLightGBMの便利さが実現できているように思った(今後調べる必要)
実際推論速度に関してはXGBoost, CatBoostに比べて最遅らしい
参考文献
pandasでmulti-hot encodingする
pivot_tableに関しては以下参照しています
やりたいこと
以下のようにpandasでlistとして保持しているカテゴリー値を

以下のようにmulti-hot encodingしたい

やり方
全体処理
以下のように、一度listを展開し、pivot_tableで集約し直すことで上記変換が可能です。
# listを展開する df = df.explode("genre") # multi-hot化 df = df.pivot_table(index=['movie_id'], columns=['genre'], aggfunc=[len], fill_value=0) # multi-levelになってるカラムなどを削除 df = df.rename_axis([None, None], axis=1) df.columns = df.columns.droplevel() df = df.reset_index()
各処理
各処理を細かくみていくと、以下になります
df

# listを展開する df = df.explode("genre") df

# multi-hot化 df = df.pivot_table(index=['movie_id'], columns=['genre'], aggfunc=[len], fill_value=0) df

# multi-levelになってるカラムなどを削除 df = df.rename_axis([None, None], axis=1) df.columns = df.columns.droplevel() df = df.reset_index()

dictで保持している特徴量のtrain_test_split
やりたいこと
以下のように辞書型で保持している特徴量を
{'field1': array([0, 1, 2, 3, 4, 5]), 'field2': array([5, 4, 3, 2, 1, 0]), 'label': array([1, 0, 1, 0, 0, 0])}
以下のように辞書型を保持したまま分割したい
{'field1': array([4, 0, 3]), 'field2': array([1, 5, 2]), 'label': array([0, 1, 0])}
{'field1': array([5, 1, 2]), 'field2': array([0, 4, 3]), 'label': array([0, 0, 1])}
やり方
クラス分布に考慮した抽出などのオプションを自分で実装するのは結構しんどいので、scikit-learnのmodel_selection.train_test_splitをラップした処理を作成する ランダムなindexの配列を作成し、train_test_splitでlabelの配列と共に分割し、各arrayからindex指定で抽出すればできた
class Splitter: def __init__(self, train_size, label_col: str): self.train_size = train_size self.label_col = label_col self.train_indices = None self.test_indices = None def set_split_indices(self, field_to_values): total_length = len(field_to_values[self.label_col]) split_indices = np.array(range(total_length)) labels = field_to_values[self.label_col] self.train_indices, self.test_indices, _, _ = train_test_split( split_indices, labels, train_size=self.train_size,stratify=labels) def split(self, field_to_values): train = {field: values[self.train_indices] for field, values in field_to_values.items()} test = {field: values[self.test_indices] for field, values in field_to_values.items()} return train, test
実行結果
>>> field_to_values = {"field1": np.array([0, 1, 2, 3, 4, 5]), "field2": np.array([5, 4, 3, 2, 1, 0]), "label": np.array([1, 0, 1, 0, 0, 0])}
>>> splitter = Splitter(train_size=0.5, label_col="label")
>>> splitter.set_split_indices(field_to_values)
>>> splitter.split(field_to_values)
({'field1': array([4, 0, 3]), 'field2': array([1, 5, 2]), 'label': array([0, 1, 0])}, {'field1': array([5, 1, 2]), 'field2': array([0, 4, 3]), 'label': array([0, 0, 1])})
今回複数辞書を同じindexで分割したかったのでクラス化したが、関数として書くと以下になる
def train_test_split_dict(field_to_values, train_size, label_col: str) total_length = len(field_to_values[label_col]) split_indices = np.array(range(total_length)) labels = field_to_values[label_col] train_indices, test_indices, _, _ = train_test_split( split_indices, labels, train_size=train_size, stratify=labels) train = {field: values[train_indices] for field, values in field_to_values.items()} test = {field: values[test_indices] for field, values in field_to_values.items()} return train, test
Pythonで不規則な2次元標準リストをflattenする
やりたいこと
[0, 0, [0, 0], 0, [0]]
みたいな不規則にlistが含まれる標準リストを以下のように平坦化したい
[0, 0, 0, 0, 0, 0]
やり方
一度全ての値をリスト化して、その上でitertools.chain.from_iterableを適用すればできた
def flatten_sequences(sequences: List[list]) -> list: sequences = [i if type(i) == list else [i] for i in sequences] flattened = list(itertools.chain.from_iterable(sequences)) return flattened
実行結果
>>> flatten_sequences([0, 0, [0, 0], 0, [0]]) [0, 0, 0, 0, 0, 0]
one-hot encodingされた特徴量を逆に元のカテゴリー値に戻す
MovieLensのデータセットがこんな感じで処理がめんどくさかったのでメモとして
やりたいこと
以下のように one-hot encoding された状態で渡されたデータセットを
movie_id action horror romance sf 0 1 1 0 0 0 1 2 0 0 1 0 2 2 1 0 0 0 3 3 0 0 0 1 4 3 1 0 0 0 5 4 0 1 0 0 6 5 0 0 0 1 7 5 0 1 0 0 8 5 1 0 0 0
以下のように one-hot encoding される前の categorical な状態に戻したい
movie_id genre 0 1 action 1 2 romance 2 2 action 3 3 sf 4 3 action 5 4 horror 6 5 sf 7 5 horror 8 5 action
やり方
以下のような関数を用意する
def convert_onehot_to_category(df, id_col, one_hot_columns, category_col='category'): df_concat = pd.DataFrame(columns=[id_col, category_col]) for col in one_hot_columns: # 値が1以上のもののみ残す df_each = df[df[col] >= 1][[id_col, col]] # 値をカテゴリー値に置き換える df_each[col] = col df_each.columns = [id_col, category_col] df_concat = pd.concat([df_concat, df_each], axis=0) # 重複削除 df_concat = df_concat.drop_duplicates().reset_index(drop=True).sort_values(by=id_col) return df_concat
以下のように、
を渡せば
genres = ['action', 'romance', 'sf', 'horror'] id_col = 'movie_id' category_col = 'genre' df_category = convert_onehot_to_category(df_onehot, id_col=id_col, one_hot_columns=genres, category_col=category_col) print(df_category)
元のカテゴリー値に変換してくれる
movie_id genre 0 1 action 1 2 action 4 2 romance 2 3 action 5 3 sf 7 4 horror 3 5 action 6 5 sf 8 5 horror
時系列に考慮したシーケンシャル・カテゴリ特徴量へのログデータの省メモリな変換
はじめに
こんにちは、今回は時系列情報を考慮する必要のあるログデータに対して、メモリ消費を抑えつつ前処理を行う方法について書いていきます。
やりたいこと
このようなユーザーごとの行動ログの入ったデータセットがあったとして、
userid itemid categoryid timestamp 0 0 3 1 2019-01-04 1 0 4 1 2019-01-08 2 0 4 1 2019-01-19 3 0 5 1 2019-01-02 4 0 7 2 2019-01-17 5 0 8 2 2019-01-07 6 1 0 0 2019-01-06 7 1 1 0 2019-01-14 8 1 2 0 2019-01-20 9 1 6 2 2019-01-01 10 1 7 2 2019-01-12 11 1 8 2 2019-01-18 12 2 3 1 2019-01-16 13 2 4 1 2019-01-15 14 2 5 1 2019-01-10 15 2 5 1 2019-01-13 16 2 6 2 2019-01-03 17 2 7 2 2019-01-05 18 2 8 2 2019-01-11 19 2 8 2 2019-01-21 20 2 9 3 2019-01-09
以下のようなユーザーごとに時間を基準にして並び替えた可変長の系列データや、
各ユーザーが接触したitemid(時系列順) [[5, 3, 8, 4, 7, 4], [6, 0, 7, 1, 8, 2], [6, 7, 9, 5, 8, 5, 4, 3, 8]] 各ユーザーが接触したcategoryid(時系列順) [[1, 1, 2, 1, 2, 1], [2, 0, 2, 0, 2, 0], [2, 2, 3, 1, 2, 1, 1, 1, 2]]
以下のような時系列を考慮したカテゴリー変数を作成したいです。 ここではitemid、categoryidに対して最新のレコードを使用するとします。
各ユーザーが接触した最新のitemid [4, 2, 8] 各ユーザーが接触した最新のcategoryid [1, 0, 2]
※ ここでは例としてECでどのカテゴリーのどの商品を見たかっていうログを想定しています。各カラムは読み替えてください。
系列データに関しては、このようなリストを作成できれば、例えば Keras (functional API) だとそれぞれ以下のようにpaddingすることで、シーケンシャルデータとして入力することができます。
import tensorflow as tf inputs = [] inputs.append(tf.keras.preprocessing.sequence.pad_sequences( df['itemid'].values.tolist(), padding='post', truncating='post', maxlen=10)) inputs.append(tf.keras.preprocessing.sequence.pad_sequences( df['categoryid'].values.tolist(), padding='post', truncating='post', maxlen=10))
Pandasでの書き方
系列データに関しては、pandasでは以下のように書くと、
# ユーザーid, 時系列順に並び替え df = df.sort_values(by=['userid','timestamp']) # ユーザー単位でリストとしてgroupby df = df.groupby('userid').agg(list).reset_index(drop=False) print('各ユーザーが接触したitemid(時系列順)') pprint.pprint(df['itemid'].values.tolist()) print('各ユーザーが接触したcategoryid(時系列順)') pprint.pprint(df['categoryid'].values.tolist()
上記の結果が得られます。
各ユーザーが接触したitemid(時系列順) [[5, 3, 8, 4, 7, 4], [6, 0, 7, 1, 8, 2], [6, 7, 9, 5, 8, 5, 4, 3, 8]] 各ユーザーが接触したcategoryid(時系列順) [[1, 1, 2, 1, 2, 1], [2, 0, 2, 0, 2, 0], [2, 2, 3, 1, 2, 1, 1, 1, 2]]
また、カテゴリデータに関しては、
# ユーザー単位で最新のものを取るようにgroupby df_cate = df.loc[df.groupby('userid')['timestamp'].idxmax()] print(df_cate) print('各ユーザーが接触した最新のitemid') pprint.pprint(df_cate['itemid'].values.tolist()) print('各ユーザーが接触した最新のcategoryid') pprint.pprint(df_cate['categoryid'].values.tolist())
のように書くことで、上記の結果を得ることができます。
各ユーザーが接触した最新のitemid [4, 2, 8] 各ユーザーが接触した最新のcategoryid [1, 0, 2]
Pandasで起こり得る問題
上記データセットが大きくなってくると、Pandasだとメモリエラーを起こし一括での変換はできなくなります。 加えて、データセット自体がメモリに乗り切らない場合も同じく処理できません。 一方で、データセットを分割して処理する場合は各データセットに含まれないレコードの時系列情報を保持する必要があります。
改めてやりたいこと
上記のような背景から、
- 前処理におけるメモリ消費を抑える
- データセットの分割した読み込みに対応できる
ような時系列順に系列データを作成できる方法が必要となり対応しました。
以下では具体的な方法に関して書いていきます。
方法
ここでは、時系列情報を保持したリストを作成し、それを元に
- 時系列を考慮した系列特徴量
- 時系列を考慮したカテゴリ特徴量
の作成方法について書きます。
その後、分割したデータセットではどのような処理を行うのか説明します。
ソート対象リストの作成
まず、時系列順の操作を行う元となるリストを作成します。
時系列順かつユーザー単位で系列データとして持ちたい値を item その値の時系列情報を timestamp とすると、
[[[item,timestamp],[item,timestamp]...[item,timestamp]], [[item,timestamp],[item,timestamp]...[item,timestamp]], ... [[item,timestamp],[item,timestamp]...[item,timestamp]]]
という3次元のリストを作成します。 ここで、1次元目はユーザーidをインデックスとします。
処理としては以下のようになります。
def create_list(df, user_index_col, sort_col, target_col, user_num): """ :param user_index_col: ユーザーIDのカラム :param sort_col: sortに使う値の入っているカラム :param target_col: sortしたいカラム :param user_num: ユーザー数(エンコーダ等から取得してください) """ inputs = [[] for _ in range(user_num)] for _, user_index, sort_value, target_value in df[[user_index_col, sort_col, target_col]].itertuples(): inputs[user_index].append([target_value, sort_value]) return inputs
最初に出てきたデータセットに対してこの処理を行うと、
itemid_inputs = create_list(df, user_index_col='userid', sort_col='timestamp', target_col='itemid', user_num=3) categoryid_inputs = create_list(df, user_index_col='userid', sort_col='timestamp', target_col='categoryid', user_num=3) print('itemid') pprint.pprint(itemid_inputs) print('categoryid') pprint.pprint(categoryid_inputs)
以下のようなリストが作成されます。
itemid
[[[3, Timestamp('2019-01-04 00:00:00')],
[4, Timestamp('2019-01-08 00:00:00')],
[4, Timestamp('2019-01-19 00:00:00')],
[5, Timestamp('2019-01-02 00:00:00')],
[7, Timestamp('2019-01-17 00:00:00')],
[8, Timestamp('2019-01-07 00:00:00')]],
[[0, Timestamp('2019-01-06 00:00:00')],
[1, Timestamp('2019-01-14 00:00:00')],
[2, Timestamp('2019-01-20 00:00:00')],
[6, Timestamp('2019-01-01 00:00:00')],
[7, Timestamp('2019-01-12 00:00:00')],
[8, Timestamp('2019-01-18 00:00:00')]],
[[3, Timestamp('2019-01-16 00:00:00')],
[4, Timestamp('2019-01-15 00:00:00')],
[5, Timestamp('2019-01-10 00:00:00')],
[5, Timestamp('2019-01-13 00:00:00')],
[6, Timestamp('2019-01-03 00:00:00')],
[7, Timestamp('2019-01-05 00:00:00')],
[8, Timestamp('2019-01-11 00:00:00')],
[8, Timestamp('2019-01-21 00:00:00')],
[9, Timestamp('2019-01-09 00:00:00')]]]
categoryid
[[[1, Timestamp('2019-01-04 00:00:00')],
[1, Timestamp('2019-01-08 00:00:00')],
[1, Timestamp('2019-01-19 00:00:00')],
[1, Timestamp('2019-01-02 00:00:00')],
[2, Timestamp('2019-01-17 00:00:00')],
[2, Timestamp('2019-01-07 00:00:00')]],
[[0, Timestamp('2019-01-06 00:00:00')],
[0, Timestamp('2019-01-14 00:00:00')],
[0, Timestamp('2019-01-20 00:00:00')],
[2, Timestamp('2019-01-01 00:00:00')],
[2, Timestamp('2019-01-12 00:00:00')],
[2, Timestamp('2019-01-18 00:00:00')]],
[[1, Timestamp('2019-01-16 00:00:00')],
[1, Timestamp('2019-01-15 00:00:00')],
[1, Timestamp('2019-01-10 00:00:00')],
[1, Timestamp('2019-01-13 00:00:00')],
[2, Timestamp('2019-01-03 00:00:00')],
[2, Timestamp('2019-01-05 00:00:00')],
[2, Timestamp('2019-01-11 00:00:00')],
[2, Timestamp('2019-01-21 00:00:00')],
[3, Timestamp('2019-01-09 00:00:00')]]]
時系列順にソート
次に、作成したリストを時系列順にソートする処理を加えます。
def sort_list(inputs, is_descending): """ :param is_descending: 降順かどうか """ return [sorted(i_input, key=lambda i: i[1], reverse=is_descending) for i_input in inputs]
この処理を行うと、
itemid_inputs = sort_list(itemid_inputs, is_descending=False) categoryid_inputs = sort_list(categoryid_inputs, is_descending=False) print('itemid') pprint.pprint(itemid_inputs) print('categoryid') pprint.pprint(categoryid_inputs)
以下のように時系列順に並び替えられたリストが作成されます。
itemid
[[[5, Timestamp('2019-01-02 00:00:00')],
[3, Timestamp('2019-01-04 00:00:00')],
[8, Timestamp('2019-01-07 00:00:00')],
[4, Timestamp('2019-01-08 00:00:00')],
[7, Timestamp('2019-01-17 00:00:00')],
[4, Timestamp('2019-01-19 00:00:00')]],
[[6, Timestamp('2019-01-01 00:00:00')],
[0, Timestamp('2019-01-06 00:00:00')],
[7, Timestamp('2019-01-12 00:00:00')],
[1, Timestamp('2019-01-14 00:00:00')],
[8, Timestamp('2019-01-18 00:00:00')],
[2, Timestamp('2019-01-20 00:00:00')]],
[[6, Timestamp('2019-01-03 00:00:00')],
[7, Timestamp('2019-01-05 00:00:00')],
[9, Timestamp('2019-01-09 00:00:00')],
[5, Timestamp('2019-01-10 00:00:00')],
[8, Timestamp('2019-01-11 00:00:00')],
[5, Timestamp('2019-01-13 00:00:00')],
[4, Timestamp('2019-01-15 00:00:00')],
[3, Timestamp('2019-01-16 00:00:00')],
[8, Timestamp('2019-01-21 00:00:00')]]]
categoryid
[[[1, Timestamp('2019-01-02 00:00:00')],
[1, Timestamp('2019-01-04 00:00:00')],
[2, Timestamp('2019-01-07 00:00:00')],
[1, Timestamp('2019-01-08 00:00:00')],
[2, Timestamp('2019-01-17 00:00:00')],
[1, Timestamp('2019-01-19 00:00:00')]],
[[2, Timestamp('2019-01-01 00:00:00')],
[0, Timestamp('2019-01-06 00:00:00')],
[2, Timestamp('2019-01-12 00:00:00')],
[0, Timestamp('2019-01-14 00:00:00')],
[2, Timestamp('2019-01-18 00:00:00')],
[0, Timestamp('2019-01-20 00:00:00')]],
[[2, Timestamp('2019-01-03 00:00:00')],
[2, Timestamp('2019-01-05 00:00:00')],
[3, Timestamp('2019-01-09 00:00:00')],
[1, Timestamp('2019-01-10 00:00:00')],
[2, Timestamp('2019-01-11 00:00:00')],
[1, Timestamp('2019-01-13 00:00:00')],
[1, Timestamp('2019-01-15 00:00:00')],
[1, Timestamp('2019-01-16 00:00:00')],
[2, Timestamp('2019-01-21 00:00:00')]]]
時系列を考慮した系列データの作成
まず、上記で作成したリストから可変長の系列特徴量(シーケンシャルな特徴量)を作成するための処理は以下になります。
def create_sequential(inputs): # リストのうちtimestampのリストを削除 return [[i[0] for i in i_input] for i_input in inputs]
これを実行すると、
print('各ユーザーが接触したitemid(時系列順)') pprint.pprint(create_sequential(itemid_inputs)) print('各ユーザーが接触したcategoryid(時系列順)') pprint.pprint(create_sequential(categoryid_inputs))
求めていた結果を得ることができます。
各ユーザーが接触したitemid(時系列順) [[5, 3, 8, 4, 7, 4], [6, 0, 7, 1, 8, 2], [6, 7, 9, 5, 8, 5, 4, 3, 8]] 各ユーザーが接触したcategoryid(時系列順) [[1, 1, 2, 1, 2, 1], [2, 0, 2, 0, 2, 0], [2, 2, 3, 1, 2, 1, 1, 1, 2]]
時系列を考慮したカテゴリデータの作成
次に、上記で作成したリストから各ユーザーの最新のレコードをカテゴリ変数として取得するための処理は以下になります。
def create_category(inputs, n=-1): """ :param n: 時系列順のリストのうち、何番目のものを残すか """ # リストのうちtimestampのリストを削除 # 時系列順の系列データのうち、n番目のもののみを残す return [[i[0] for i in i_input][n] for i_input in inputs]
これを実行すると、
print('各ユーザーが接触した最新のitemid') pprint.pprint(create_category(itemid_inputs, -1)) print('各ユーザーが接触した最新のcategoryid') pprint.pprint(create_category(categoryid_inputs, -1))
以下のように求めていた結果を得ることができます。
各ユーザーが接触した最新のitemid [4, 2, 8] 各ユーザーが接触した最新のcategoryid [1, 0, 2]
処理まとめ
ここで、上記説明のために分けていた関数を統合すると以下のようになります。
def create_features( df, user_index_col, sort_col, target_col, user_num, is_descending, is_sequence, n=-1): """ :param user_index_col: ユーザーIDのカラム :param sort_col: sortに使う値の入っているカラム :param target_col: sortしたいカラム :param user_num: ユーザー数(エンコーダ等から取得してください) :param is_descending: 降順かどうか :param is_sequence: シーケンシャルかどうか :param n: 時系列順のリストのうち、何番目のものを残すか(カテゴリーのみ) """ # リストの作成 inputs = [[] for _ in range(user_num)] for _, user_index, sort_value, target_value in df[[user_index_col, sort_col, target_col]].itertuples(): inputs[user_index].append([target_value, sort_value]) # リストのソート inputs = [sorted(i_input, key=lambda i: i[1], reverse=is_descending) for i_input in inputs] if is_sequence: return [[i[0] for i in i_input] for i_input in inputs] else: return [[i[0] for i in i_input][n] for i_input in inputs]
データを分割して読み込む場合の方法
ここが一番書きたかったところで、上記のように時系列情報を保持するようにリストを作成すると、全データをメモリに乗せることができない場合等、データセットを分割して読み込み分割単位ごとに前処理を行うという場合にも対応できます。
例として、以下のように最初のDataFrameが三つに分割されてdictionaryに格納されたものがあるとして、 (実際にないケースな気がしますが、例示として、、、)
{'df1': userid itemid categoryid timestamp
0 0 3 1 2019-01-04
1 0 4 1 2019-01-08
2 0 4 1 2019-01-19
3 0 5 1 2019-01-02
4 0 7 2 2019-01-17
5 0 8 2 2019-01-07
6 1 0 0 2019-01-06,
'df2': userid itemid categoryid timestamp
7 1 1 0 2019-01-14
8 1 2 0 2019-01-20
9 1 6 2 2019-01-01
10 1 7 2 2019-01-12
11 1 8 2 2019-01-18
12 2 3 1 2019-01-16
13 2 4 1 2019-01-15,
'df3': userid itemid categoryid timestamp
14 2 5 1 2019-01-10
15 2 5 1 2019-01-13
16 2 6 2 2019-01-03
17 2 7 2 2019-01-05
18 2 8 2 2019-01-11
19 2 8 2 2019-01-21
20 2 9 3 2019-01-09}
リストに時系列情報を保持しているため、例えば以下のように関数を変更することで処理が可能です。
def create_features_by_datasets( df_dict, user_index_col, sort_col, target_col, user_num, is_descending, is_sequence, n=-1): inputs = [[] for _ in range(user_num)] # データセットの分割単位ごとに対して処理 for df in df_dict.values(): for _, user_index, sort_value, target_value in df[[user_index_col, sort_col, target_col]].itertuples(): inputs[user_index].append([target_value, sort_value]) inputs = [sorted(i_input, key=lambda i: i[1], reverse=is_descending) for i_input in inputs] if is_sequence: return [[i[0] for i in i_input] for i_input in inputs] else: return [[i[0] for i in i_input][n] for i_input in inputs]
以下の処理を行うと、
print('各ユーザーが接触したitemid(時系列順)') pprint.pprint(create_features_by_datasets(df_dict, user_index_col='userid', sort_col='timestamp', target_col='itemid', user_num=3, is_descending=False, is_sequence=True)) print('各ユーザーが接触した最新のitemid') pprint.pprint(create_features_by_datasets(df_dict, user_index_col='userid', sort_col='timestamp', target_col='itemid', user_num=3, is_descending=False, is_sequence=False))
結果としては上記と同じものが得られます。
各ユーザーが接触したitemid(時系列順) [[5, 3, 8, 4, 7, 4], [6, 0, 7, 1, 8, 2], [6, 7, 9, 5, 8, 5, 4, 3, 8]] 各ユーザーが接触した最新のitemid [4, 2, 8]
時系列情報以外でのソート
また、今回はソートする基準を時系列情報に絞りましたが、他のカラムで、もしくは降順でソートすることも可能です。 上記の処理に対して渡す変数を変更することで、昇順降順、カラムを指定したソートが可能です。
例えば、以下のようなデータセットにおいて、
userid itemid categoryid score 0 0 3 1 0.730968 1 0 3 1 0.889117 2 0 3 1 0.714828 3 0 4 1 0.430737 4 0 5 1 0.734746 5 0 7 2 0.412346 6 1 0 0 0.660430 7 1 3 1 0.095672 8 1 4 1 0.985072 9 1 5 1 0.629274 10 1 6 2 0.617733 11 1 7 2 0.636219 12 1 8 2 0.246769 13 1 8 2 0.020140 14 2 0 0 0.812525 15 2 1 0 0.671100 16 2 2 0 0.174011 17 2 2 0 0.164321 18 2 3 1 0.783329 19 2 4 1 0.068837 20 2 5 1 0.265281
スコアというカラムがあったとして、それで高い順に系列データやカテゴリデータを作成したい場合は以下のような処理になります。
print('スコア順(itemid)') pprint.pprint(create_features(df, user_index_col='userid', sort_col='score', target_col='itemid', user_num=3, is_descending=True, is_sequence=True)) print('スコア最大(itemid)') pprint.pprint(create_features(df, user_index_col='userid', sort_col='score', target_col='itemid', user_num=3, is_descending=True, is_sequence=False, n=0))
結果は以下のようになります。
スコア順(itemid) [[3, 5, 3, 3, 4, 7], [4, 0, 7, 5, 6, 8, 3, 8], [0, 3, 1, 5, 2, 2, 4]] スコア最大(itemid) [3, 4, 0]
終わりに
今回は、時系列情報を考慮しつつ、省メモリにログデータを系列特徴量やカテゴリ特徴量に変換する方法について書きました。 より良い方法あれば、コメントなどで教えていただきたいです。ありがとうございました。