【論文紹介】Factorization Machines
Factorization Machinesを読んで実装してみました
論文内容
課題
既存手法として、SVMやMatrixFactorizationが存在するが、
- レコメンドでよくある問題設定、つまりカテゴリー値が多い(=sparseである)入力において、SVMだと非線形なカーネル空間となるため安定してパラメータを学習できない
- matrix factorizationはsparseな入力をうまく学習できるが、2種類の特徴量間の交互作用のみしか考慮できない
そのため、sparseな入力に対してもmatrix factorizationのようにうまく学習ができて、一方でSVMのように様々な特徴量を入力できるモデルとして、Factorization Machinesを提案
想定する入力
下記のように、UserのItemに対する評価をターゲットラベルとして、User*Itemの値でユニークとなる
- one-hot(User, Movie, Last Movie Rated)
- multi-hot(Other Movie Rated)
- 連続値(Time)
で構成された入力を考えます。

Factorization Machines

equationはこちらになります。 ここで、nがfeature数、iが何次元目のfeatureかを示します。
そして、左項がlinear regressionで、各featureに対して単純に重みを掛け合わせて足し合わせたもの。 右項がfeature同士の交互作用を考慮するもの(feature intaractions)になっています。
ここで、kをハイパーパラメータである潜在ベクトルの次元として、

であり、対象となる2種類のfeatureの潜在ベクトル間の交互作用を考慮するものになっています。
xixjは両方のfeatureにおいて値が存在するか(=0でない)を表すシグナルとなっています。
このことから、例えば、上記入力の7行目のレコードを考えると、

右項は、
<UserC, vMovieSW> + <UserC, vOtherMoviesTI> + <UserC, OtherMoviesSW> + ... + <OtherMoviesSW, Time> + <Time, LastMovieTI>
といった組み合わせでそれぞれ潜在ベクトルのdot積が計算されていくというのが、右項のやっていることになります。 またここで、各featureの潜在ベクトルは同じ一つの潜在空間に属します。
なぜsparsityに強いのか
課題として、汎用的な入力を受け付けることとsparsityに強いことが挙げられていましたが、前者に関しては既に明確ですが、後者に関しては、存在しないfeature間の組み合わせに対しても、類似する組み合わせを元に推定できるからというのが理由になります。
feature間の組み合わせ間でそのラベルの値が類似する場合に、その交互作用同士は類似すると考えられるため、類似する組み合わせに含まれるfeatureも、潜在空間において近い位置にあると考えられるためです。
multi-way Factorization Machines
上記Factorization Machinesでは一つの組み合わせに対して2種類のfeature間の交互作用のみを考慮しましたが、それ以上の種類を考慮することが下式のように可能です。
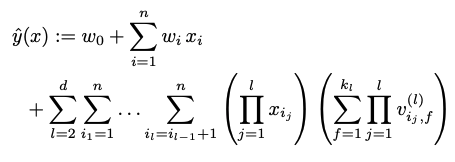
例えば3-way、つまり3種類のfeature間の交互作用を考慮する場合は、上記の例だと以下のような組み合わせになります。
<UserC, vMovieSW, vOtherMoviesTI> + <UserC, vOtherMoviesTI, OtherMoviesSW> + ... + <OtherMoviesSW, Time, LastMovieTI>
ただ、こちらは計算コスト的に厳しそうです。
実用時の注意点
計算コストの削減
上記Factorization Machinesにおけるequationだと、全てのfeature間の組み合わせを計算する必要があるため、計算コストはfeature数nに対して2乗分増えていきます。 その代替案として、右項を以下のように変形することで、feature数に対して線形に増加するように計算コストを下げることができます。

モデルを実装する際は右項をこちらに置き換えてやる必要があります。
潜在ベクトルの次元kの設定
理論上は、kの値が充分以上大きければ、どんな交互作用でも表現可能となります。 ただ、データセットの中に全通りの組み合わせが存在することは稀であるため、通常はそれ以下の値で設定するのが良いとのことです。
また、汎化性能を上げる、つまりモデルの表現力を抑制するためにkの値を小さくすることも考えられます。
実装
モデルの実装は以下になります。
- Embedding Layerを動的に作成したかったため、initでfeatureの情報を渡している
- Embedding Layerでsequencialな特徴量を扱えるようにしている
ため、Embedding Layerのみ少し複雑になっています。
from collections import OrderedDict import tensorflow as tf class EmbeddingLayer(tf.keras.layers.Layer): def __init__(self, features_info, emb_dim, name_prefix=''): """ sequence対応のembedding layer """ super(EmbeddingLayer, self).__init__() self.features_info = features_info self.feature_to_embedding_layer = OrderedDict() for feature in features_info: initializer = tf.keras.initializers.RandomNormal(stddev=0.01, seed=None) if feature['is_sequence']: # sequenceのembedding self.feature_to_embedding_layer[feature['name']] = tf.keras.layers.Embedding( feature['dim'], emb_dim, mask_zero=True, name=f"embedding_{name_prefix}{feature['name']}", embeddings_initializer=initializer) else: self.feature_to_embedding_layer[feature['name']] = tf.keras.layers.Embedding( feature['dim'], emb_dim, name=f"embedding_{name_prefix}{feature['name']}", embeddings_initializer=initializer) def concatenate_embeddings(self, embeddings, name_prefix=''): if len(embeddings) >= 2: embeddings = tf.keras.layers.Concatenate(axis=1, name=name_prefix+'embeddings_concat')(embeddings) else: embeddings = embeddings[0] return embeddings def call(self, inputs): embeddings = [] for feature_input, feature in zip(inputs, self.features_info): # embeddingの作成 embedding = self.feature_to_embedding_layer[feature['name']](feature_input) if feature['is_sequence']: # sequenceの場合はaverage pooling embedding = tf.math.reduce_mean(embedding, axis=1, keepdims=True) embeddings.append(embedding) # concatenate embeddings = self.concatenate_embeddings(embeddings) return embeddings class FactorizeLayer(tf.keras.layers.Layer): def __init__(self, features_info, latent_dim=5): super(FactorizeLayer, self).__init__() self.embedding = EmbeddingLayer(features_info, latent_dim, 'factorize_') def call(self, inputs): # factorization embeddings = self.embedding(inputs) # 元論文のlemma 3.1 summed_square = tf.square(tf.reduce_sum(embeddings, axis=1)) squared_sum = tf.reduce_sum(tf.square(embeddings), axis=1) output = tf.subtract(summed_square, squared_sum) output = tf.multiply(0.5, tf.reduce_sum(output, axis=1, keepdims=True)) return output
最後に
- 存在しない組み合わせに対しての推定が可能
- interaction以外の特徴量も入力可能(性別とか)
という2点から、User*Itemのレコメンドを考えたときに、コールドスタートに非常に強いモデルであるように思いました。